Latest Posts
See what's new
What is Pooling in a Convolutional Neural Network (CNN): Pooling Layers Explained
On December 5, 2021 In Computer Vision, Deep Learning, Machine Learning
Pooling in convolutional neural networks is a technique for generalizing features extracted by convolutional filters and helping the network recognize features independent of their location in the image. Why Do We Need Pooling in a CNN? Convolutional layers are the basic building blocks of a convolutional neural network used for computer vision applications such
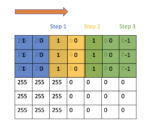
Understanding Padding and Stride in Convolutional Neural Networks
On December 3, 2021 In Computer Vision, Deep Learning, Machine Learning
Padding describes the addition of empty pixels around the edges of an image. The purpose of padding is to preserve the original size of an image when applying a convolutional filter and enable the filter to perform full convolutions on the edge pixels. Stride in the context of convolutional neural networks describes the process
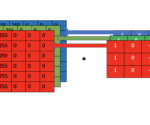
Understanding Convolutional Filters and Convolutional Kernels
On November 29, 2021 In Computer Vision, Deep Learning, Machine Learning
This post will introduce convolutional kernels and discuss how they are used to perform 2D and 3D convolution operations. We also look at the most common kernel operations, including edge detection, blurring, and sharpening. A convolutional filter is a filter that is applied to manipulate images or extract structures and features from an image.
What is a Convolution: Introducing the Convolution Operation Step by Step
On November 21, 2021 In Computer Vision, Deep Learning, Machine Learning
In this post, we build an intuitive step-by-step understanding of the convolution operation and develop the mathematical definition as we go. A convolution describes a mathematical operation that blends one function with another function known as a kernel to produce an output that is often more interpretable. For example, the convolution operation in a
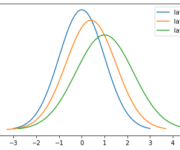
What is Batch Normalization And How Does it Work?
On November 15, 2021 In Deep Learning, Machine Learning
Batch normalization is a technique for standardizing the inputs to layers in a neural network. Batch normalization was designed to address the problem of internal covariate shift, which arises as a consequence of updating multiple-layer inputs simultaneously in deep neural networks. What is Internal Covariate Shift? When training a neural network, it will speed
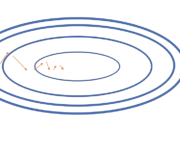
Deep Learning Optimization Techniques for Gradient Descent Convergence
On November 11, 2021 In Deep Learning, Machine Learning
In this post, we will introduce momentum, Nesterov momentum, AdaGrad, RMSProp, and Adam, the most common techniques that help gradient descent converge faster. Understanding Exponentially Weighted Moving Averages A core mechanism behind many of the following algorithms is called an exponentially weighted moving average. As the name implies, you calculate an average of several
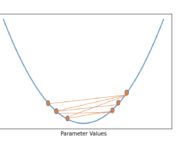
Stochastic Gradient Descent versus Mini Batch Gradient Descent versus Batch Gradient Descent
On November 6, 2021 In Deep Learning, Machine Learning
In this post, we will discuss the three main variants of gradient descent and their differences. We look at the advantages and disadvantages of each variant and how they are used in practice. Batch gradient descent uses the whole dataset, known as the batch, to compute the gradient. Utilizing the whole dataset returns a
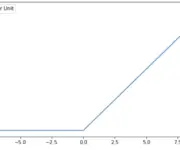
Understanding The Exploding and Vanishing Gradients Problem
On October 31, 2021 In Deep Learning, Machine Learning
In this post, we develop an understanding of why gradients can vanish or explode when training deep neural networks. Furthermore, we look at some strategies for avoiding exploding and vanishing gradients. The vanishing gradient problem describes a situation encountered in the training of neural networks where the gradients used to update the weights shrink
Dropout Regularization in Neural Networks: How it Works and When to Use It
On October 27, 2021 In Deep Learning, Machine Learning
In this post, we will introduce dropout regularization for neural networks. We first look at the background and motivation for introducing dropout, followed by an explanation of how dropout works conceptually and how to implement it in TensorFlow. Lastly, we briefly discuss when dropout is appropriate. Dropout regularization is a technique to prevent neural
Weight Decay in Neural Networks
On October 16, 2021 In Deep Learning, Machine Learning
What is Weight Decay Weight decay is a regularization technique in deep learning. Weight decay works by adding a penalty term to the cost function of a neural network which has the effect of shrinking the weights during backpropagation. This helps prevent the network from overfitting the training data as well as the exploding