Deep Learning Archive

What is the Best Math Course for Machine Learning
On June 7, 2022 In Deep Learning, Machine Learning, Mathematics for Machine Learning
Learning the required mathematics is often perceived as one of the biggest obstacles by people trying to get started in machine learning. Mathematical concepts from linear algebra, statistics, and calculus are foundational to many machine learning algorithms. Luckily, the past several years have seen the proliferation of several online courses and other learning resources.

Foundations of Deep Learning for Object Detection: From Sliding Windows to Anchor Boxes
On May 12, 2022 In Computer Vision, Deep Learning, Machine Learning
In this post, we will cover the foundations of how neural networks learn to localize and detect objects. Object Localization vs. Object Detection Object localization refers to the practice of detecting a single prominent object in an image or a scene, while object detection is about detecting several objects. A neural network can localize
How to Learn TensorFlow Fast: A Learning Roadmap with Resources
On April 21, 2022 In Deep Learning, Machine Learning
TensorFlow is one of the two dominant deep learning frameworks. It is heavily used in industry to build cutting-edge AI applications. While its rival PyTorch has seen an increase in popularity over recent years, TensorFlow is still the dominant framework in industry applications. Most machine learning engineers, especially deep learning engineers, are well-advised to

Deep Learning for Semantic Image Segmentation: A Worked Example in TensorFlow
On March 18, 2022 In Computer Vision, Deep Learning, Machine Learning
In this post, we will develop a practical understanding of deep learning for image segmentation by building a UNet in TensorFlow and using it to segment images. What is Image Segmentation? Image Segmentation is a technique in digital image processing that describes the process of partitioning an image into sections. Often the goal is
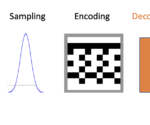
An Introduction to Autoencoders and Variational Autoencoders
On February 13, 2022 In Computer Vision, Deep Learning, Machine Learning
What is an Autoencoder? An autoencoder is a neural network trained to compress its input and recreate the original input from the compressed data. This procedure is useful in applications such as dimensionality reduction or file compression where we want to store a version of our data that is more memory efficient or reconstruct
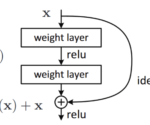
An Introduction to Residual Skip Connections and ResNets
On February 1, 2022 In Deep Learning, Machine Learning
In this post, we will develop a thorough understanding of skip connections and how they help in the training of deep neural networks. Furthermore, we will have a look at ResNet50, a popular architecture based on skip connections. What are Residual Skip Connections? In a nutshell, skip connections are connections in deep neural networks
Building a Convolutional Neural Network for Image Classification: A Step-by-Step Example in TensorFlow
On January 26, 2022 In Deep Learning, Machine Learning
In this post, we will learn to build a basic convolutional neural network in TensorFlow and how to train it to distinguish between cats and dogs. We start off with a simple neural network and gradually work our way towards more complex architectures evaluating at each step how the results are changing. To build

Deep Learning Architectures for Image Classification: LeNet vs Alexnet vs VGG
On January 18, 2022 In Computer Vision, Deep Learning, Machine Learning
In this post, we will develop a foundational understanding of deep learning for image classification. Then we will look at the classic neural network architectures that have been used for image processing. Deep Learning for Image Classification Image classification in deep learning refers to the process of getting a deep neural network to determine
Building a Neural Network with Training Pipeline in TensorFlow and Python for the Titanic Dataset: A Step-by-Step Example
On January 8, 2022 In Deep Learning, Machine Learning
In this post, we will cover how to build a simple neural network in Tensorflow for a spreadsheet dataset. In addition to constructing a model, we will build a complete preprocessing and training pipeline in Tensorflow that will take the original dataset as an input and automatically transform it into the format necessary for
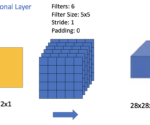
An Introduction to Convolutional Neural Network Architecture
On December 12, 2021 In Computer Vision, Deep Learning, Machine Learning
In this post, we understand the basic building blocks of convolutional neural networks and how they are combined to form powerful neural network architectures for computer vision. We start by looking at convolutional layers, pooling layers, and fully connected. Then, we take a step-by-step walkthrough through a simple CNN architecture. Understanding Layers in a