Latest Posts
See what's new
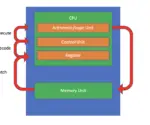
How does a CPU Execute Instructions: Understanding Instruction Cycles
On October 15, 2021 In Computer Architecture
In this post, we will understand how a CPU executes instructions on a high level by illustrating the instruction cycle using a step-by-step example. We also cover interrupts and how they affect the instruction cycle. A CPU executes instructions using a cycle of steps known as the instruction cycle. What is an Instruction Cycle?
Feature Scaling and Data Normalization for Deep Learning
On October 5, 2021 In Deep Learning, Machine Learning, None
Before training a neural network, there are several things we should do to prepare our data for learning. Normalizing the data by performing some kind of feature scaling is a step that can dramatically boost the performance of your neural network. In this post, we look at the most common methods for normalizing data
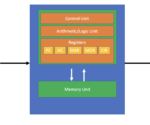
What is the Von Neumann Architecture
On October 4, 2021 In Computer Architecture
The von Neumann architecture is a foundational computer hardware architecture that most modern computer systems are built upon. It consists of the control unit, the arithmetic, and logic unit, the memory unit, registers, and input and output devices. The key features of the von Neumann architecture are: Data as well as the program operating
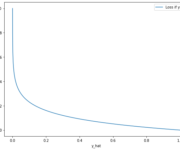
An Introduction to Neural Network Loss Functions
On September 28, 2021 In Deep Learning, Machine Learning
This post introduces the most common loss functions used in deep learning. The loss function in a neural network quantifies the difference between the expected outcome and the outcome produced by the machine learning model. From the loss function, we can derive the gradients which are used to update the weights. The average over
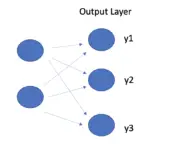
Understanding Basic Neural Network Layers and Architecture
On September 21, 2021 In Deep Learning, Machine Learning
This post will introduce the basic architecture of a neural network and explain how input layers, hidden layers, and output layers work. We will discuss common considerations when architecting deep neural networks, such as the number of hidden layers, the number of units in a layer, and which activation functions to use. In our
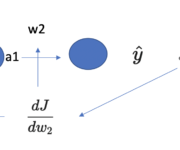
Understanding Backpropagation With Gradient Descent
On September 13, 2021 In Deep Learning, Machine Learning
In this post, we develop a thorough understanding of the backpropagation algorithm and how it helps a neural network learn new information. After a conceptual overview of what backpropagation aims to achieve, we go through a brief recap of the relevant concepts from calculus. Next, we perform a step-by-step walkthrough of backpropagation using an
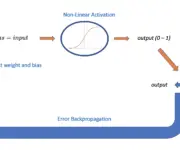
How do Neural Networks Learn
On September 3, 2021 In Deep Learning, Machine Learning
In this post, we develop an understanding of how neural networks learn new information. Neural networks learn by propagating information through one or more layers of neurons. Each neuron processes information using a non-linear activation function. Outputs are gradually nudged towards the expected outcome by combining input information with a set of weights that
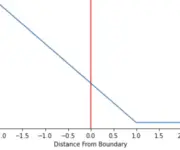
Understanding Hinge Loss and the SVM Cost Function
On August 22, 2021 In Classical Machine Learning, Machine Learning, None
In this post, we develop an understanding of the hinge loss and how it is used in the cost function of support vector machines. Hinge Loss The hinge loss is a specific type of cost function that incorporates a margin or distance from the classification boundary into the cost calculation. Even if new observations
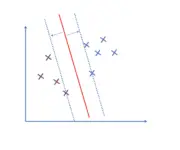
What is a Support Vector?
On August 17, 2021 In Classical Machine Learning, Machine Learning
In this post, we will develop an understanding of support vectors, discuss why we need them, how to construct them, and how they fit into the optimization objective of support vector machines. A support vector machine classifies observations by constructing a hyperplane that separates these observations. Support vectors are observations that lie on the
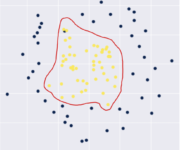
What is a Kernel in Machine Learning?
On August 11, 2021 In Classical Machine Learning, Machine Learning
In this post, we are going to develop an understanding of Kernels in machine learning. We frame the problem that kernels attempt to solve, followed by a detailed explanation of how kernels work. To deepen our understanding of kernels, we apply a Gaussian kernel to a non-linear problem. Finally, we briefly discuss the construction