None Archive
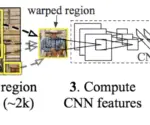
Deep Learning Architectures for Object Detection: Yolo vs. SSD vs. RCNN
On May 22, 2022 In None
In this post, we will look at the major deep learning architectures that are used in object detection. We first develop an understanding of the region proposal algorithms that were central to the initial object detection architectures. Then we dive into the architectures of various forms of RCNN, YOLO, and SSD and understand what
Feature Scaling and Data Normalization for Deep Learning
On October 5, 2021 In Deep Learning, Machine Learning, None
Before training a neural network, there are several things we should do to prepare our data for learning. Normalizing the data by performing some kind of feature scaling is a step that can dramatically boost the performance of your neural network. In this post, we look at the most common methods for normalizing data
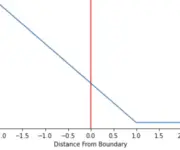
Understanding Hinge Loss and the SVM Cost Function
On August 22, 2021 In Classical Machine Learning, Machine Learning, None
In this post, we develop an understanding of the hinge loss and how it is used in the cost function of support vector machines. Hinge Loss The hinge loss is a specific type of cost function that incorporates a margin or distance from the classification boundary into the cost calculation. Even if new observations
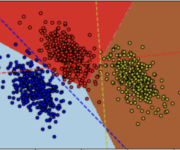
The Softmax Function and Multinomial Logistic Regression
On May 4, 2021 In Classical Machine Learning, Machine Learning, None
In this post, we will introduce the softmax function and discuss how it can help us in a logistic regression analysis setting with more than two classes. This is known as multinomial logistic regression and should not be confused with multiple logistic regression which describes a scenario with multiple predictors. What is the Softmax
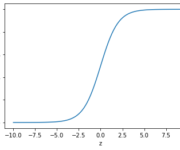
The Sigmoid Function and Binary Logistic Regression
On May 3, 2021 In Classical Machine Learning, Machine Learning, None
In this post, we introduce the sigmoid function and understand how it helps us to perform binary logistic regression. We will further discuss the gradient descent for the logistic regression model (logit model). In linear regression, we are constructing a regression line of the form y = kx + d. Within the specified range,

Type 1 and Type 2 Error
On April 18, 2021 In Mathematics for Machine Learning, None, Probability and Statistics
When you are testing hypotheses, you might encounter type 1 and type 2 errors. Identifying them and dealing with them is essential for setting up statistical testing scenarios. They also play a huge role in machine learning. What is a Type 1 Error in Statistics? When you reject the null hypothesis although it is

Gamma Distribution
On March 3, 2021 In Mathematics for Machine Learning, None, Probability and Statistics
In this post we build an intuitive understanding of the Gamma distribution by going through some practical examples. Then we dive into the mathematical background and introduce the formulas. The gamma distribution models the wait time until a certain number of continuously occurring, independent events have happened. If you are familiar with the Poisson
Probability and Statistics for Machine Learning and Data Science
On February 6, 2021 In Mathematics for Machine Learning, None, Probability and Statistics
This series of blog posts introduces probability and mathematical statistics. While I wrote these posts with a focus on machine learning and data science applications, they are kept sufficiently general for other readers. Some familiarity with vectors and matrices, as well as differential and integral calculus, is necessary to fully understand all concepts. If

What is a Diagonal Matrix
On November 25, 2020 In None
We introduce and discuss the applications and properties of the diagonal matrix, the upper triangular matrix, and the lower triangular matrix. A diagonal matrix is a square matrix in which all entries are zero, except for those on the leading diagonal. It is also called the scaling matrix because multiplication with the diagonal matrix
Gaussian Elimination and Gauss Jordan Elimination: An Introduction
On November 25, 2020 In None
We introduce Gaussian elimination and Gauss Jordan Elimination, more commonly known as the elimination method, and learn to use these methods to solve linear equations with several unknown variables. We also introduce the row echelon form of a matrix and discuss the difference between Gaussian elimination and Gauss Jordan elimination. Gaussian Elimination Method Gaussian
- 1
- 2