Feature Scaling and Data Normalization for Deep Learning

Before training a neural network, there are several things we should do to prepare our data for learning. Normalizing the data by performing some kind of feature scaling is a step that can dramatically boost the performance of your neural network. In this post, we look at the most common methods for normalizing data and how to do it in Tensorflow. We also briefly discuss the most important steps to take in addition to normalization before you even think about training a neural network.
Normalization in deep learning refers to the practice of transforming your data so that all features are on a similar scale, usually ranging from 0 to 1. This is especially useful when the features in a dataset are on very different scales.
Note that the term data normalization also refers to the restructuring of databases to bring tables into a normal form. Always consider the context!
Why do we Normalize/Standardize Data?
In a dataset, features usually have different units and, therefore, different scales. For example, a dataset used to predict housing prices may contain the size in sqft or square meters, the number of bedrooms and bathrooms on a simple numeric scale, the age of the property in years, etc.
The size of the properties available in a particular area might range from 500 to 10000 square foot while the number of bathrooms ranges from 1 to 5. This means you have not only very different scales but also different ranges for the variance.
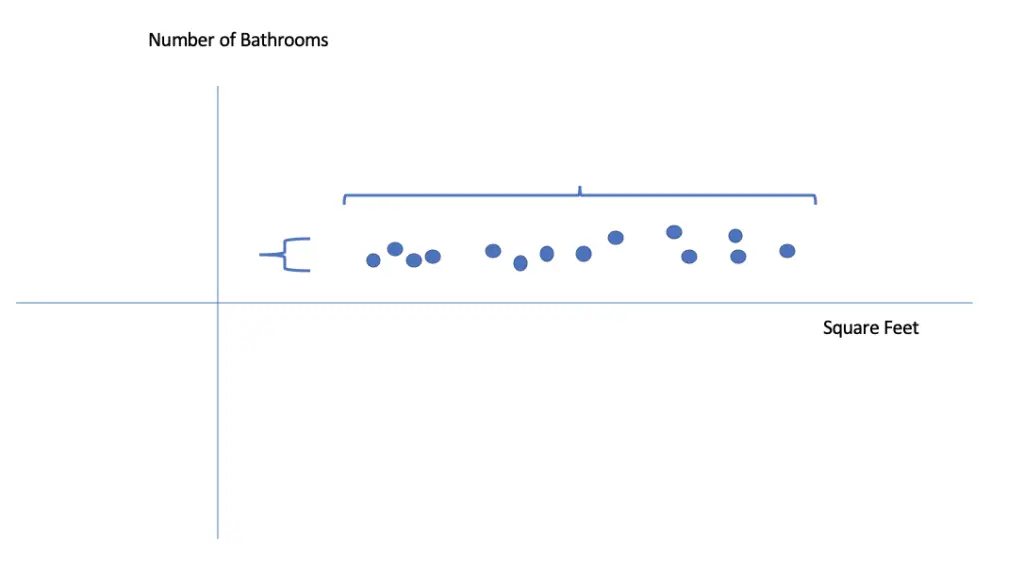
Since the update to the weights depends on the input values, gradient descent will update some weights much faster than others. This makes it harder to converge on an optimal value.
When should you Normalize/Standardize
As a general rule, I would always normalize the data. Doing so can dramatically improve the performance of your model, while not normalizing will almost never hurt your model. It is especially important when the algorithm you apply involves gradient descent.
Standard Normalization
The most commonly applied type of normalization transforms all features to have a mean 0 and standard deviation of 1.
In machine learning, we usually operate under the assumption that features are distributed according to a Gaussian distribution. The standard Gaussian bell curve, also known as the standard normal distribution, has a mean of 0 and a standard deviation of 1.
Setting the mean to 0 is achieved by calculating the current mean for each variable x (each of which has n entries).
\mu = \frac{1}{n} \sum ^n_{i=1} x_iThen you subsequently subtract the mean from each variable x to obtain your rescaled x with a new mean of 0.
x = x - \mu
Next, you need to calculate the standard deviation.
\sigma = \sqrt{\frac{1}{n} \sum ^n_{i=1} (x_i- \mu)^2 }Note that since the mean is already zero, we do not need to subtract the standard deviation anymore.
Lastly, you divide your variables (features) by the standard deviation.
x = \frac{x}{\sigma}If you have a background in statistics, you might recognize that this process is equivalent to calculating z scores that are commonly used for constructing confidence intervals.
z = \frac{x-\mu}{\sigma}It is, therefore, sometimes referred to as z-score normalization.
Normalization in TensorFlow
In Tensorflow, you can normalize your data by adding a normalization layer.
import tensorflow as tf import numpy as np norm = tf.keras.layers.experimental.preprocessing.Normalization()
When you pass your training data to the normalization layer, using the adapt method, the layer will calculate the mean and standard deviation of the training set and store them as weights. It will apply normalization to all subsequent inputs based on these weights. So if we use the same dataset, it will perform normalization as described above.
norm.adapt(data) #pass the same data used for adaption will normalize the data norm(data)

If we pass different data as input, it will apply normalization based on the mean and standard deviation of the data passed for adaption.
adapt_data = np.array([2., 3., 12.], dtype='float32') input_data = np.array([5., 6., 7.], dtype='float32') norm = tf.keras.layers.experimental.preprocessing.Normalization() norm.adapt(adapt_data) norm(input_data)

Tensorflow thus makes it easy to normalize your data as part of the model by simply passing in a normalization layer at the appropriate locations.
Min-Max Scaling
Sometimes, min-max scaling is applied as an alternative to normalization. Note that min-max scaling is also often referred to as normalization. You perform min-max scaling according to the following formula.
x = \frac{x-x_{min}}{x_{max}-x_{min}}Since you are dividing by the maximum difference between values in your dataset, all of your values should fall between 0 and 1.
This is different from the standard normalization discussed above, where you merely ensure that your values have a standard deviation equal to one. This means with standard normalization; you will generally have larger standard deviations and values that are larger than 1 in your data.
In neural networks, you generally should use data where observations lie in a range between 0 and 1. In the context of deep learning, min-max normalization should therefore be your first choice.
For example, images usually have three color channels with pixel values ranging from 0 to 255. So if you are training a neural network on an image classification task, it is good practice to scale your pixels to a value between 0 and 1 by dividing by 255.
Min-Max Scaling in Tensorflow
In Tensorflow, this can easily be done by including a rescaling layer as the first layer in your network.
import tensorflow as tf data = np.array([5., 6., 7.], dtype='float32') min_max = tf.keras.layers.experimental.preprocessing.Rescaling(1./255) min_max(data)
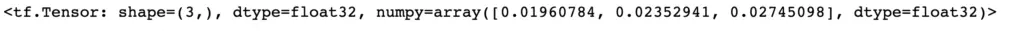
When dealing with images, you should also pass the input shape of your image, usually consisting of its width, height, and the number of channels (3 for RGB).
min_max = tf.keras.layers.experimental.preprocessing.Rescaling(1./255, input_shape=(width, height, 3))
Prerequisites to Normalization and Learning
Before you standardize/normalize your data and train a neural network, you need to make sure that the following requirements are met. These steps are an essential part of any kind of data preprocessing you are likely to perform in the context of a deep learning project.
Handling Missing Values
Real-world datasets are rarely complete. Therefore, you need a strategy for handling missing values, such as removing or imputing them.
Creating Numeric Features
Often your data will come in the form of text strings. For example, categories might be described using words rather than ordinal numbers. You need to convert those features consisting of non-numeric data to numeric entries.
Creating Fixed Size Inputs
Neural networks expect a standard size and format. For instance, in the context of image processing, this means all images should have standard width, height, and number of channels.
This article is part of a blog post series on the foundations of deep learning. For the full series, go to the index.



{kind=link}