What is a Support Vector?

In this post, we will develop an understanding of support vectors, discuss why we need them, how to construct them, and how they fit into the optimization objective of support vector machines.
A support vector machine classifies observations by constructing a hyperplane that separates these observations.
Support vectors are observations that lie on the margin surrounding the data-separating hyperplane. Since the margin defines the minimum distance observations should have from the plane, the observations that lie on the margin impact the orientation and position of the hyperplane.
Why Do We Need Support Vectors?
When data is linearly separable, there are several possible orientations and positions for the hyperplane.
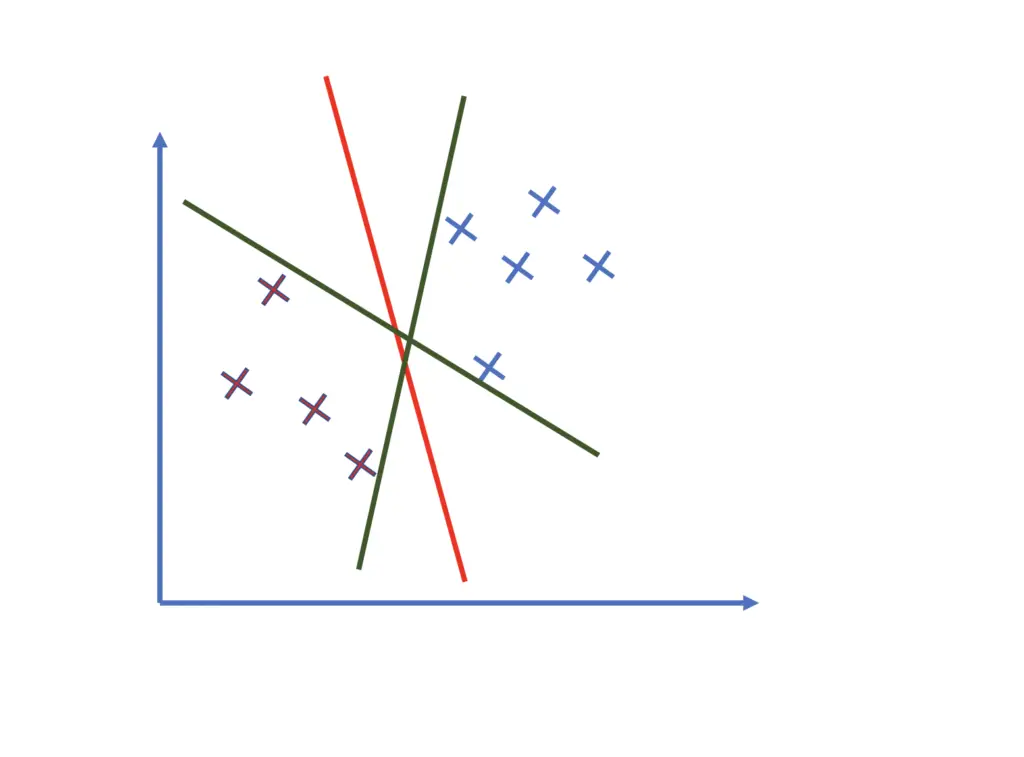
In the illustration above, all of the hyperplanes perfectly separate the observations. Which of them is the best choice?
In addition to separating the training data, we also want the classifier to maximize the overall distance between the classifier and the points. This gives us a certain margin that maximizes our confidence in the prediction. If all the training points have had a certain minimum distance from the hyperplane, we can be more confident that any new observations that maintain that minimum distance are classified correctly.
If, on the other hand, some observations are very close to the plane, new observations with similar characteristics that deviate slightly could well end up on the other side of the hyperplane. Therefore, the red hyperplane is a better choice than the green hyperplanes.
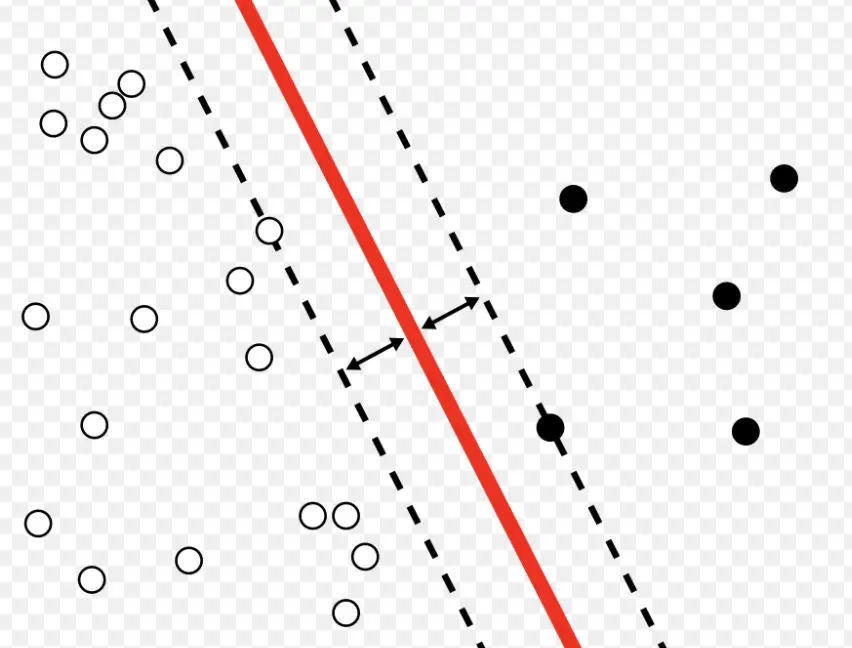
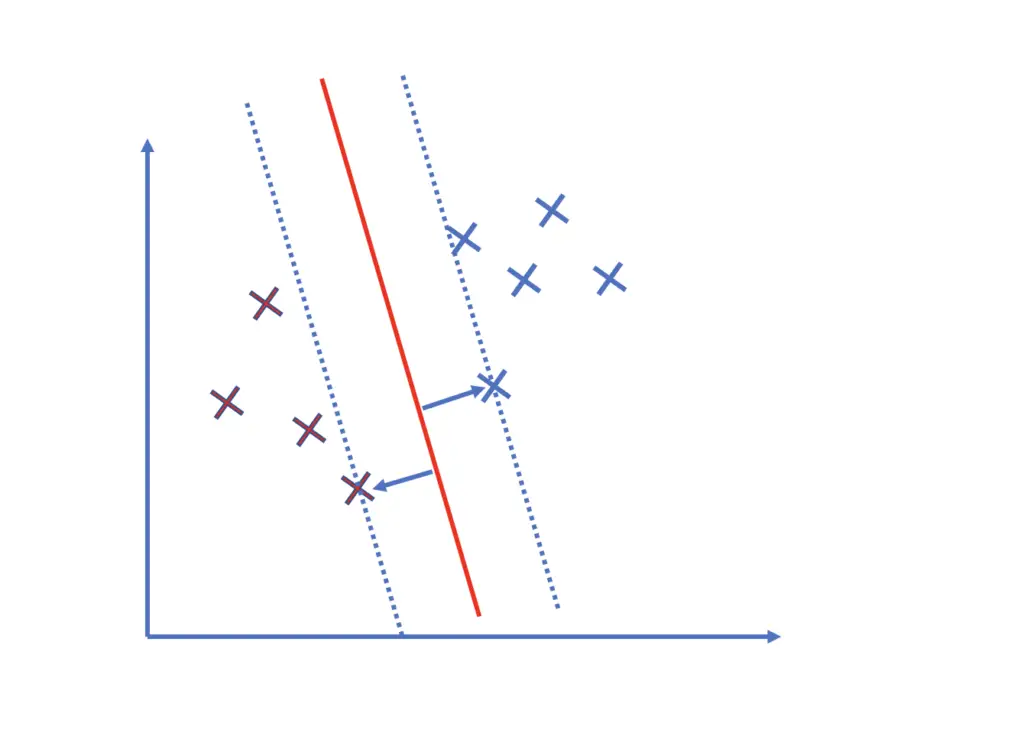
The observations that are closest to the hyperplane are especially important because they lie directly on the margin. They influence the orientation and position of the hyperplane the most and determine how wide the margin is.
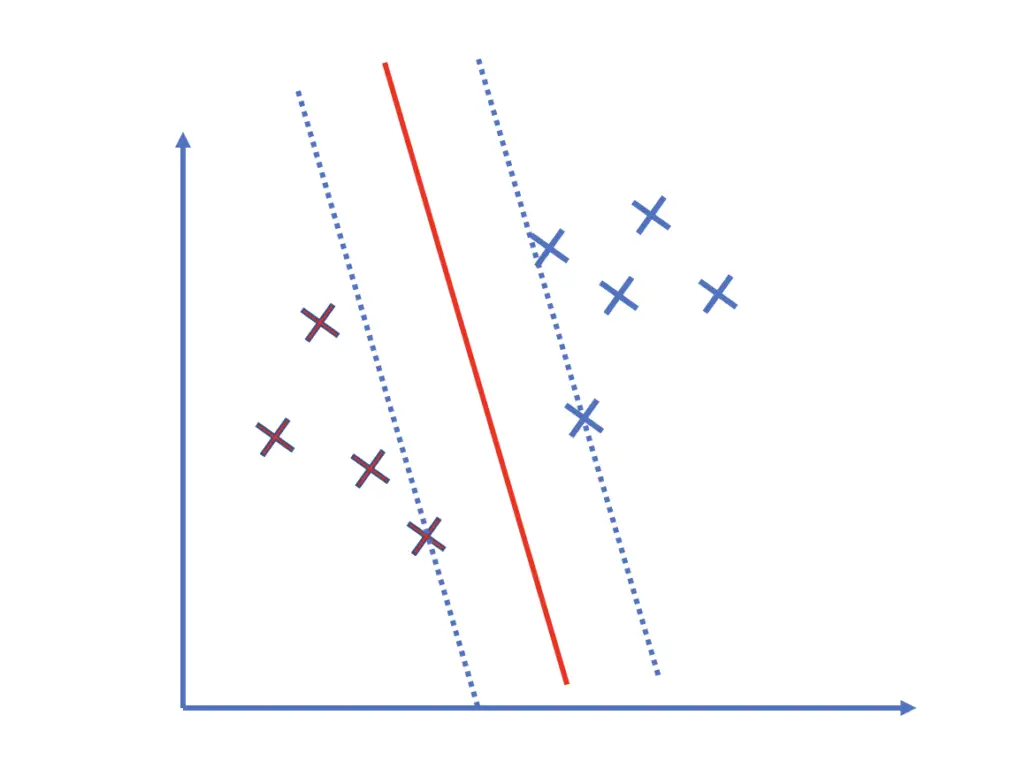
If we add just one observation that is closer to the margin, the hyperplane may change significantly.
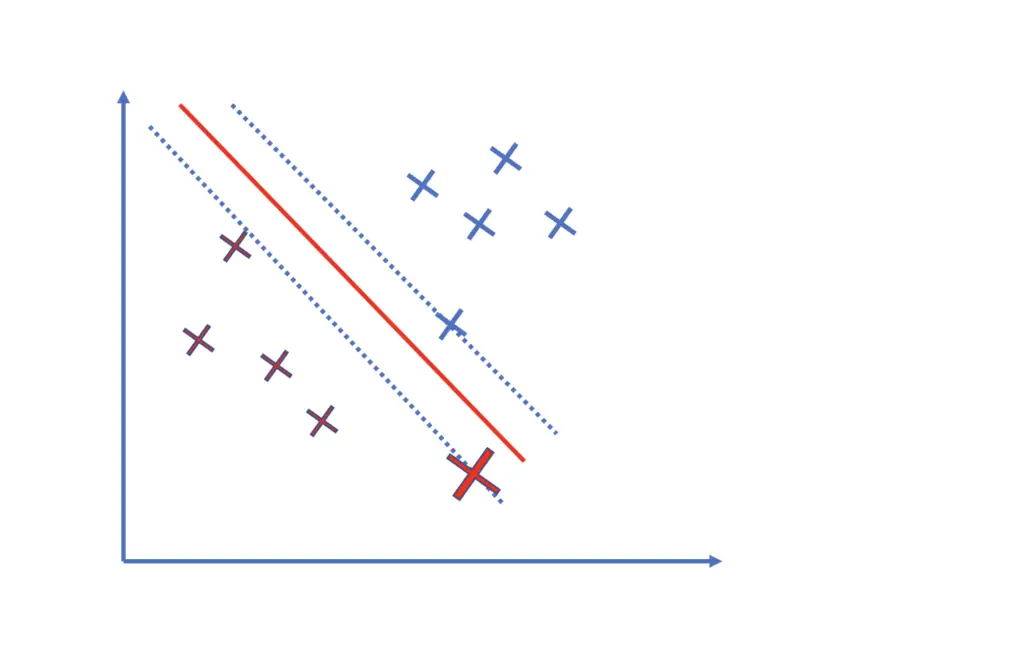
The observations closest to the plane support the plane and hold it in place. It is a bit like the essential pillars that support a roof.
How do Support Vectors Work
You construct hyperplanes by maximizing a margin around the hyperplane. You find the margin and, in extension, the position of the hyperplane by finding the minimum distance between the plane and the closest examples.
How do you find the minimum distance to the closest observation?
The minimum distance between an observation x_1 and the hyperplane can be measured along a line that is orthogonal to the plane and goes through x_1. We call this orthogonal line w. To simplify the example, we assume we’ve already determined that x_1 and x_2 are the support vectors. the points closest to the hyperplane) on each side and that the hyperplane also goes through the origin.
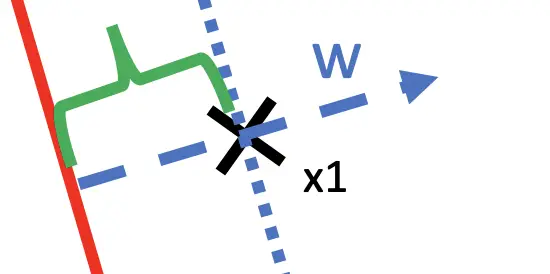
The point x_1’s coordinates constitute a vector from the origin. For example, if the point x_1 has coordinates [3,5], the associated vector will equal [3,5].
x_1 = [3,5]
Assuming that your hyperplane also goes through the origin, you can find the shortest distance between x_1 and the plane by performing a vector projection p of x1 onto the orthogonal vector w.
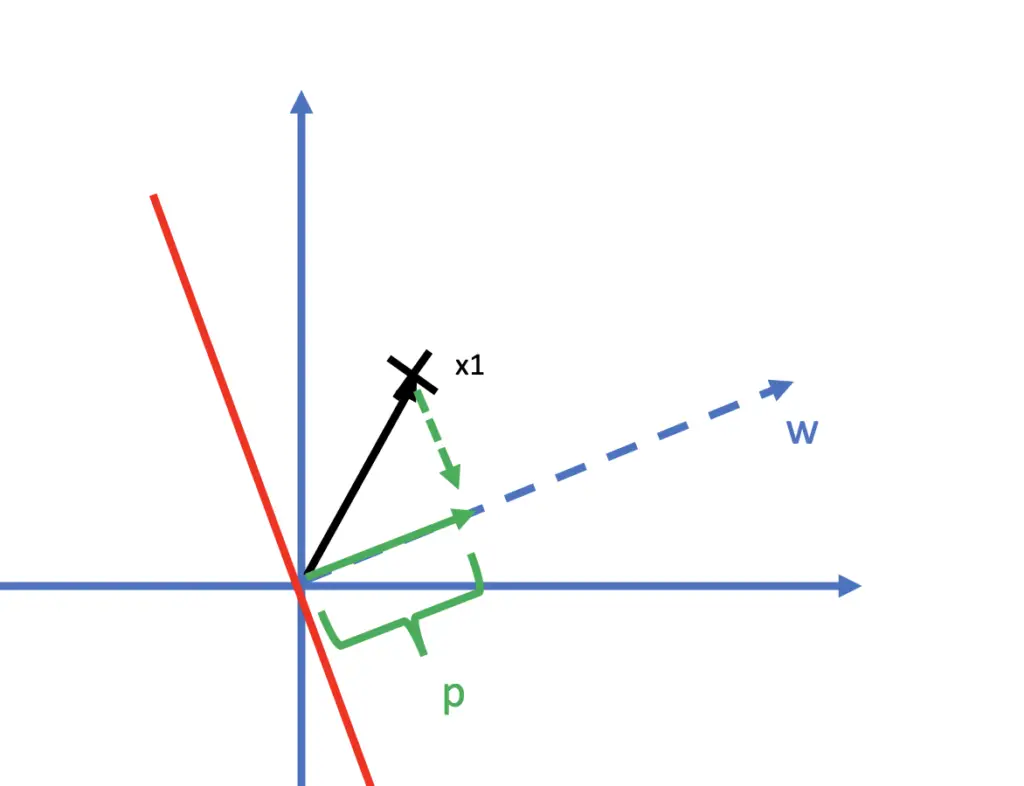
If you are not familiar with vector projections, you can check out my blog post on them. You calculate the projection of p by taking the dot product between the transpose of w and x_1 divided by the norm of w.
p = \frac{w^Tx_1}{||w||}We need to repeat the same procedure for the support vector x_2 on the other side of the hyperplane. Essentially, that gives us the following expression.
(-)p = \frac{w^Tx_2}{||w||}Note that we can arbitrarily scale the vector w. This allows us to get rid of the division by simply scaling w to unit length. That way, the norm of w equals 1, and the division becomes obsolete.
p = \frac{w^Tx_1}{1} = w^Tx_2To remove the constraint that w has to go through the origin, we can add an intercept term b. Now we end up with the characteristic equation for a line that defines our margin m.
Pos\; Margin:\; m = w^Tx_1 + b
Accordingly, the margin on the other side of the hyperplane is defined by
Neg\; Margin:\; -m = w^Tx_1 + b
We can use the same equation to find the hyperplane. The hyperplane is exactly in the middle between the two margins. Therefore, it equals zero (You can verify this by adding up the two margins).
Hyperplane:\; w^Tx_1 + b = 0
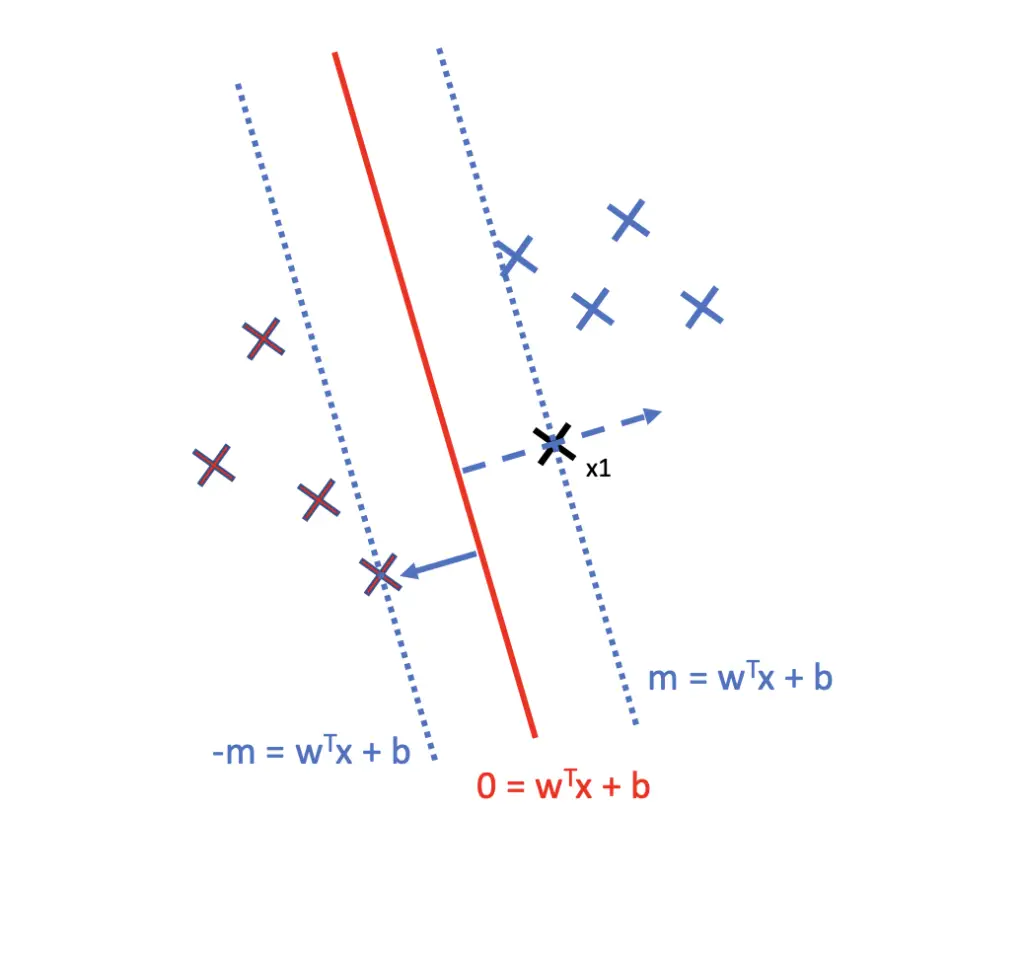
We now know how the support vectors help construct the margin by finding a projection onto a vector that is perpendicular to the separating hyperplane. We also know how to find the equation that defines our margins and our hyperplane. But do we find the optimal margin and the corresponding support vectors?
How Do We Find Support Vectors?
To increase the confidence in our predictions, we want to position the hyperplane so that the margin around the plane is maximized while the overall distance of the points is minimized. Essentially we need to set this up as an optimization problem. Unfortunately, an optimization that involves both maximizing a term and minimizing another one is very complex.
To make optimization easier, a common approach is to scale the equation defining our margin so that the margin equals 1 and -1, respectively. To achieve this goal, we scale the vector w and the entire vector space until the margin m equals 1.
w^Tx_1 + b = 1
Scaling w implies that the length of w (||w||), which we previously eliminated by setting it equal to 1, will change as well. To maintain the original form of the equation, we, therefore, have to correct our estimates by a factor of
\frac{1}{||w||}Furthermore, all future datapoints x_n should lie outside the margin, which results in the following constraints:
w^Tx_n + b \geq 1 \\ or \\ w^Tx_n + b \leq -1 \\
By setting the margin to a fixed value and constraining the data points to simply lie beyond that margin, we have simplified the optimization objective significantly. To arrive at our optimal hyperplane, all we have to do is maximize the correction factor.
max(\frac{1}{||w||})
Maximizing the inverse of the norm is equivalent to minimizing the norm. Remember that the norm is a quadratic expression. In a two-dimensional vector space, the norm or length of a vector can be calculated according to the Pythagorean theorem using the coordinates w_1 and w_2.
\sqrt{w_1^2 + w_2^2} = ||w||To save ourselves the calculation of the square root of a potentially very large term, we can also optimize the squared norm. More generally, we then want to optimize the following term.
\min_{w} \frac{1}{2} \sum^n_{i=1}w_i^2The 1/2 is a convenience term introduced to simplify the calculation when taking the derivative.
I will cover further details of the optimization algorithm and the associated cost function in my next post.
Summary
Support vectors are observations that lie closest to a separating hyperplane applied by support vector machines. They help determine the position and orientation of the plane to maximize the margin around the plane.
Support vectors and their associated distances from the hyperplane are found by projecting the observations closest to the plane onto a vector perpendicular to the plane. The overall positioning is achieved by mathematical optimization.



{kind=link}