Calculus Archive

Calculus For Machine Learning and Data Science
On December 31, 2020 In Calculus, Mathematics for Machine Learning
This series of blog posts introduces multivariate calculus for machine learning. While the first few posts should be accessible to anyone with a high-school math background, the articles covering vector calculus require a basic understanding of linear algebra. If you need a refresher, I’d suggest you first check out my series on linear algebra.
The Fundamental Theorem of Calculus and Integration
On December 31, 2020 In Calculus, Mathematics for Machine Learning
In this post, we introduce and develop an intuitive understanding of integral calculus. We learn how the fundamental theorem of calculus relates integral calculus to differential calculus. Integration is the reverse operation of differentiation. Together they form a powerful toolset to describe non-linear functions. While differentiation enables us to describe the gradient or rate

Lagrange Multipliers: An Introduction to Constrained Optimization
On December 28, 2020 In Calculus, Mathematics for Machine Learning
In this post we explain constrained optimization using LaGrange multipliers and illustrate it with a simple example. Lagrange multipliers enable us to maximize or minimize a multivariable function given equality constraints. This is useful if we want to find the maximum along a line described by another function. The Lagrange Multiplier Method Let’s say

Understanding The Gradient Descent Algorithm
On December 24, 2020 In Calculus, Mathematics for Machine Learning
In this post, we introduce the intuition as well as the math behind gradient descent, one of the foundational algorithms in modern artificial intelligence. Motivation for Gradient Descent In many engineering applications, you want to find the optimum of a complex system. For example, in a production system, you want to find the ideal

Linearization of Differential Equations for Approximation
On December 23, 2020 In Calculus, Mathematics for Machine Learning
In this post we learn how to build linear approximations to non-linear functions and how to measure the error between our approximation and the desired function. Given a well-behaved higher-order function, we can find an approximation using Taylor series. But how do we know when our approximation is good enough so that we can

Power Series: Understand the Taylor and MacLaurin Series
On December 21, 2020 In Calculus, Mathematics for Machine Learning
In this post, we introduce power series as a method to approximate unknown functions. We derive the Maclaurin series and the Taylor series in simple and intuitive terms. Differential calculus is an amazing tool to describe changes in complex systems with multiple inputs. But to unleash the power of Calculus, we need to describe

The Multivariable Chain Rule
On December 17, 2020 In Calculus, Mathematics for Machine Learning
In this post we learn how to apply the chain rule to vector-valued functions with multiple variables. We’ve seen how to apply the chain rule to real number functions. Now we can extend this concept into higher dimensions. How does the Multivariable Chain Rule Work? Remember that the chain rule helps us differentiate nested

The Hessian Matrix: Finding Minima and Maxima
On December 17, 2020 In Calculus, Mathematics for Machine Learning
In this post, we learn how to construct the Hessian matrix of a function and find out how the Hessian helps us determine minima and maxima. What is a Hessian Matrix? The Jacobian matrix helps us find the local gradient of a non-linear function. In many applications, we are interested in optimizing a function.
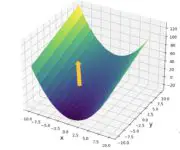
The Jacobian Matrix: Introducing Vector Calculus
On December 16, 2020 In Calculus, Mathematics for Machine Learning
We learn how to construct and apply a matrix of partial derivatives known as the Jacobian matrix. In the process, we also introduce vector calculus. The Jacobian matrix is a matrix containing the first-order partial derivatives of a function. It gives us the slope of the function along multiple dimensions. Previously, we’ve discussed how

How to Take Partial Derivatives
On December 15, 2020 In Calculus, Mathematics for Machine Learning
We learn how to take partial derivatives and develop an intuitive understanding of them by calculating the change in volume of a cylinder. Lastly, we explore total derivatives. Up until now, we’ve always differentiated functions with respect to one variable. Many real-life problems in areas such as physics, mechanical engineering, data science, etc., can
- 1
- 2