Dropout Regularization in Neural Networks: How it Works and When to Use It

In this post, we will introduce dropout regularization for neural networks. We first look at the background and motivation for introducing dropout, followed by an explanation of how dropout works conceptually and how to implement it in TensorFlow. Lastly, we briefly discuss when dropout is appropriate.
Dropout regularization is a technique to prevent neural networks from overfitting. Dropout works by randomly disabling neurons and their corresponding connections. This prevents the network from relying too much on single neurons and forces all neurons to learn to generalize better.
Why Do We Need Dropout
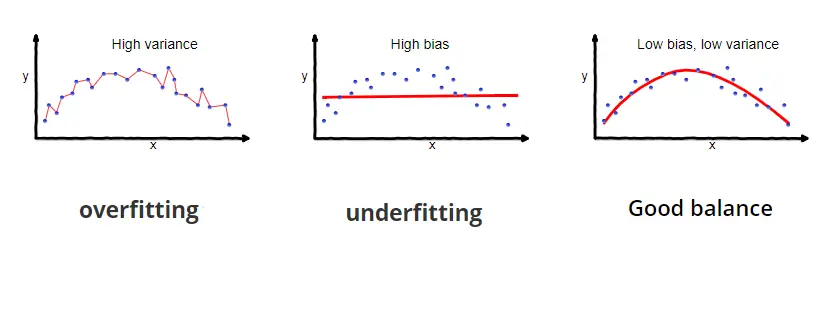
Deep neural networks are arguably the most powerful machine learning models available to us today. Due to a large number of parameters, they can learn extremely complex functions. But this also makes them very prone to overfitting the training data.
Compared to other regularization methods such as weight decay, or early stopping, dropout also makes the network more robust. This is because when applying dropout, you are removing different neurons on every pass through the network. Thus, you are actually training multiple networks with different compositions of neurons and averaging their results.
One common way of achieving model robustness in machine learning is to train a collection of models and average their results. This approach, known as ensemble learning, helps correct the mistakes produced by single models. Ensemble methods work best when the models differ in their architectures and are trained on different subsets of the training data.
In deep learning, this approach would become prohibitively expensive since training a single neural network already takes lots of time and computational power. This is especially true for applications in computer vision and natural language processing, where datasets commonly consist of many millions of training examples. Furthermore, there may not be enough labeled training data to train different models on different subsets.
Dropout mitigates these problems. Since the model drops random neurons with every pass through the network, it essentially creates a new network on every pass. But weights are still shared between these networks contrary to ensemble methods, where each model needs to be trained from scratch.
The authors who first proposed dropout (Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov) explain the main benefit of dropout as reducing the occurrence of coadaptations between neurons.
Coadaptions occur when neurons learn to fix the mistakes made by other neurons on the training data. The network thus becomes very good at fitting the training data. But it also becomes more volatile because the coadaptions are so attuned to the peculiarities of the training data that they won’t generalize to the test data.
Here is the original article on dropout regularization if you are interested in learning more details. It is definitely worth a read!
How Dropout Works
To apply dropout, you need to set a retention probability for each layer. The retention probability specifies the probability that a unit is not dropped. For example, if you set the retention probability to 0.8, the units in that layer have an 80% chance of remaining active and a 20% chance of being dropped.
Standard practice is to set the retention probability to 0.5 for hidden layers and to something close to 1, like 0.8 or 0.9 on the input layer. Output layers generally do not apply dropout.
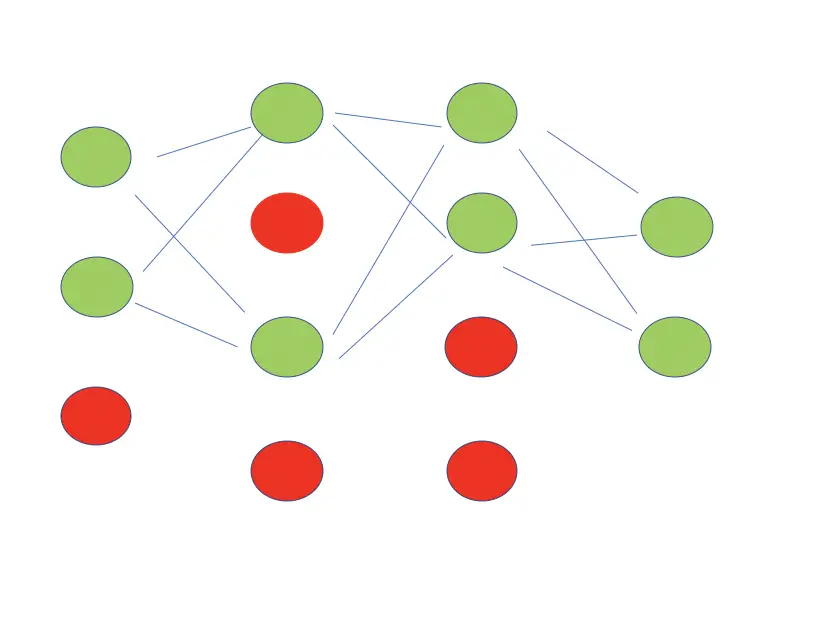
In practice, dropout is applied by creating a mask for each layer and filling it with values between 0 and 1 generated by a random number generator according to the retention probability. Each neuron with a corresponding retention probability below the specified threshold is kept, while the other ones are removed. For example, for the first hidden layer in the network above, we would create a mask with four entries.
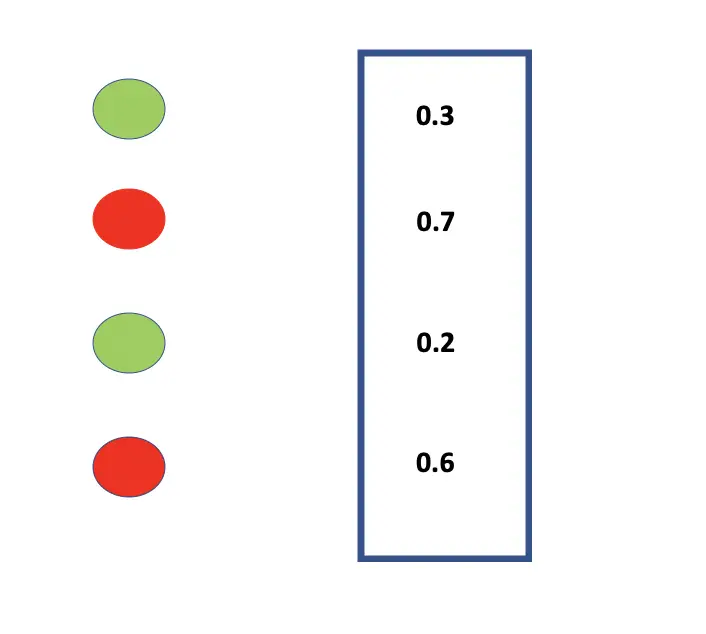
Alternatively, we could also fill the mask with random boolean values according to the retention probability. Neurons with a corresponding “True” entry are kept while those with a “False” value are discarded.

Dropout at Test Time
Dropout is only used during training to make the network more robust to fluctuations in the training data. At test time, however, you want to use the full network in all its glory. In other words, you do not apply dropout with the test data and during inference in production.
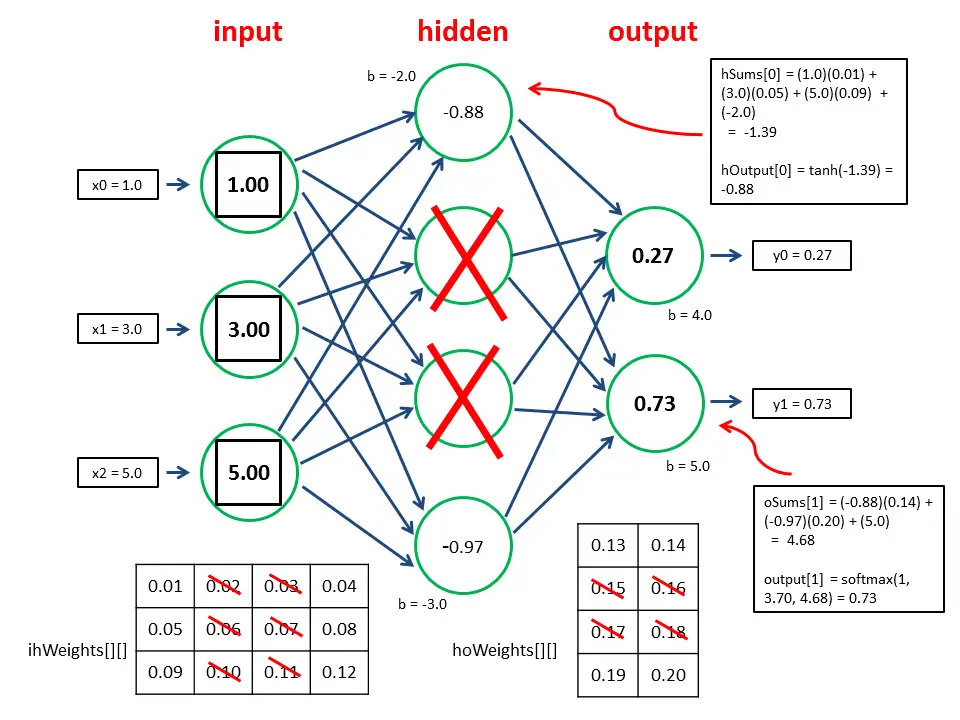
But that means your neurons will receive more connections and therefore more activations during inference than what they were used to during training. For example, if you use a dropout rate of 50% dropping two out of four neurons in a layer during training, the neurons in the next layer will receive twice the activations during inference and thus become overexcited. Accordingly, the values produced by these neurons will, on average, be too large by 50%. To correct this overactivation at test and inference time, you multiply the weights of the overexcited neurons by the retention probability (1 – dropout rate) and thus scale them down.
The following graphic by the user Dmytro Prylipko on Datascience Stackexchange nicely illustrates how this works in practice.
Inverted Dropout
An alternative to scaling the activations at test and inference time by the retention probability is to scale them at training time.
You do this by dropping out the neurons and immediately afterward scaling them by the inverse retention probability.
activation \times \frac{1}{retention\, probability}This operation scales the activations of the remaining neurons up to make up for the signal from the other neurons that were dropped.
This corrects the activations right at training time. Accordingly, it is often the preferred option.
Dropout Regularization in TensorFlow
When it comes to applying dropout in practice, you are most likely going to use it in the context of a deep learning framework. In deep learning frameworks, you usually add an explicit dropout layer after the hidden layer to which you want to apply dropout with the dropout rate (1 – retention probability) set as an argument on the layer. The framework will take care of the underlying details, such as creating the mask.
Using TensorFlow, we start by importing the dropout layer, along with the dense layer and the Sequential API from Tensorflow in Python. If you don’t have TensorFlow installed, head over to the TensorFlow documentation for instructions on how to install it.
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout
In a simple neural network that consists of a sequence of dense layers, you add dropout to a dense layer by adding an additional “Dropout” layer right after the dense layer. The following code creates a neural network of two dense layers. We add dropout with a rate of 0.2 to the first dense layer and dropout with a rate of 0.5 to the second dense layer. We assume that our dataset has six dimensions which is why we set the input shape parameter equal to 6.
model = Sequential([
Dense(64, activation='relu', input_shape=(6,)),
Dropout(0.2),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(3, activation='softmax')
])
When is Dropout Appropriate?
Dropout is an extremely versatile technique that can be applied to most neural network architectures. It shines especially when your network is very big or when you train for a very long time, both of which put a network at a higher risk of overfitting.
When you have very large training data sets, the utility of regularization techniques, including dropout, declines because the network has more data available to learn to generalize better. When the number of training examples is very limited (<5000 according to the original dropout article linked above), other techniques are more effective. Here, again, I suggest reading the original dropout article for more information.
Dropout is especially popular in computer vision applications because vision systems almost never have enough training data. The most commonly applied deep learning models in computer vision are convolutional neural networks. However, dropout is not particularly useful on convolutional layers. The reason for this is that dropout aims to build robustness by making neurons redundant. A model should learn parameters without relying on single neurons. This is especially useful when your layer has a large number of parameters. Convolutional layers have far fewer parameters and therefore generally need less regularization.
Accordingly, in convolutional neural networks, you will mostly find dropout layers after fully connected layers but not after convolutional layers. More recently, dropout has largely been replaced by other regularizing techniques such as batch normalization in convolutional architectures.
This article is part of a blog post series on the foundations of deep learning. For the full series, go to the index.

{kind=link}