Residuals and the Least Squares Regression Line

In this post, we will introduce linear regression analysis. The focus is on building intuition and the math is kept simple. If you want a more mathematical introduction to linear regression analysis, check out this post on ordinary least squares regression.
Machine learning is about trying to find a model or a function that describes a data distribution. One of the simplest predictive models consists of a line drawn through the data points known as the least-squares regression line. Unless all the data points lie in a straight line, it is impossible to perfectly predict all points using a linear prediction method like a linear regression line. This is where residuals and the least-squares method come into play.
What is the Least Squares Method?
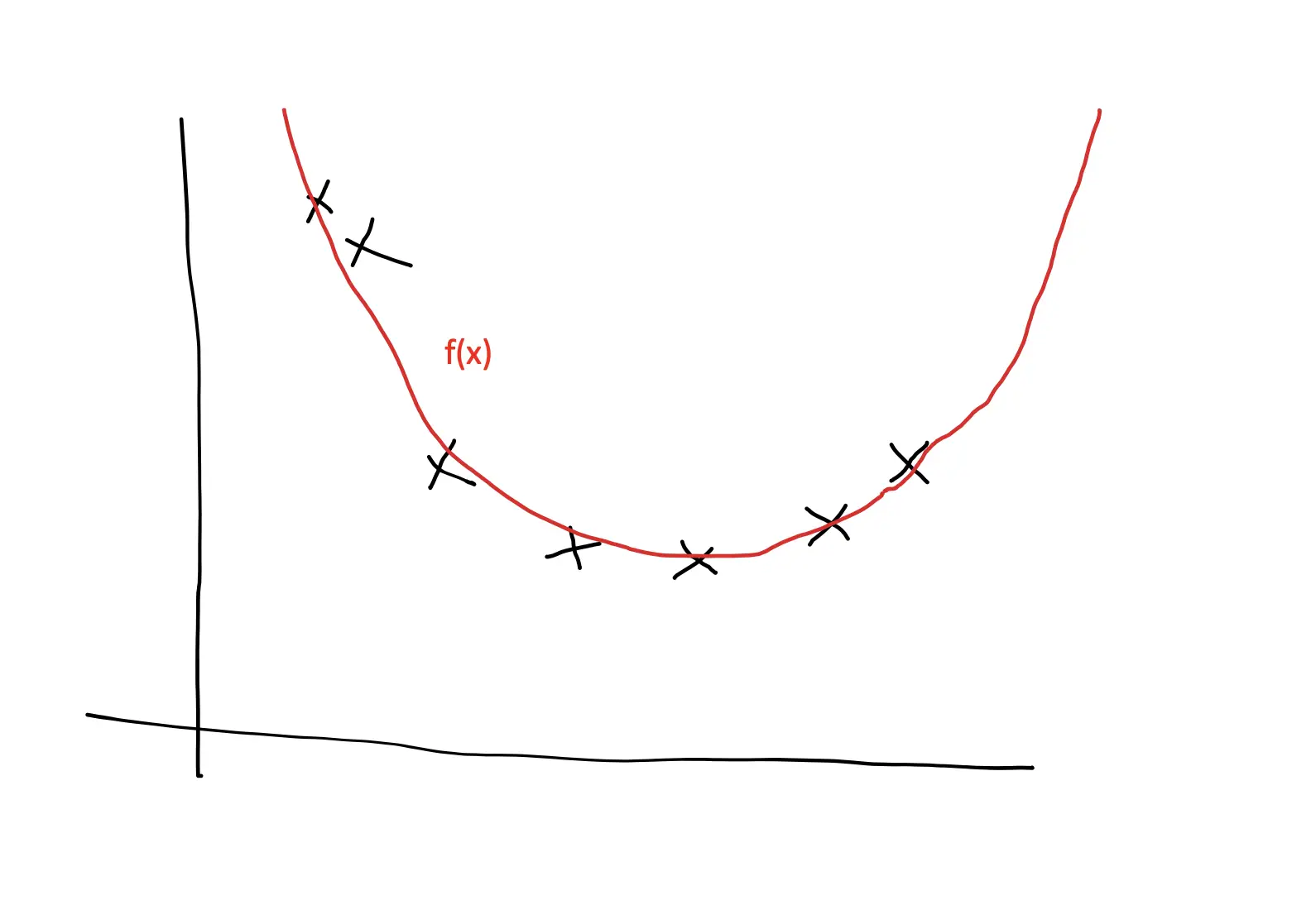
In the example plotted below, we cannot find a line that goes directly through all the data points, we instead settle on a line that minimizes the distance to all points in our dataset. This is known as the least-squares method because it minimizes the squared distance between the points and the line.
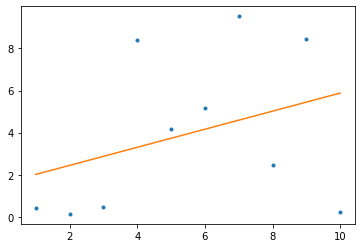
Of course, we could also apply a non-linear predictive model which could fit the data perfectly and go through all the data points. In fact, this is what more advanced machine learning models do. But this opens a host of other problems. First of all, non-linear functions are mathematically much more complicated and thus more difficult to interpret. Second, the more closely you fit a model to a specific data distribution, the less likely it is to perform well once the data distribution changes. Addressing this problem is one of the central problems in machine learning and is known as the bias-variance tradeoff.
So we’ll stick with a linear model for now
What Are Residuals?
The differences between the regression line and the actual data points are known as residuals.
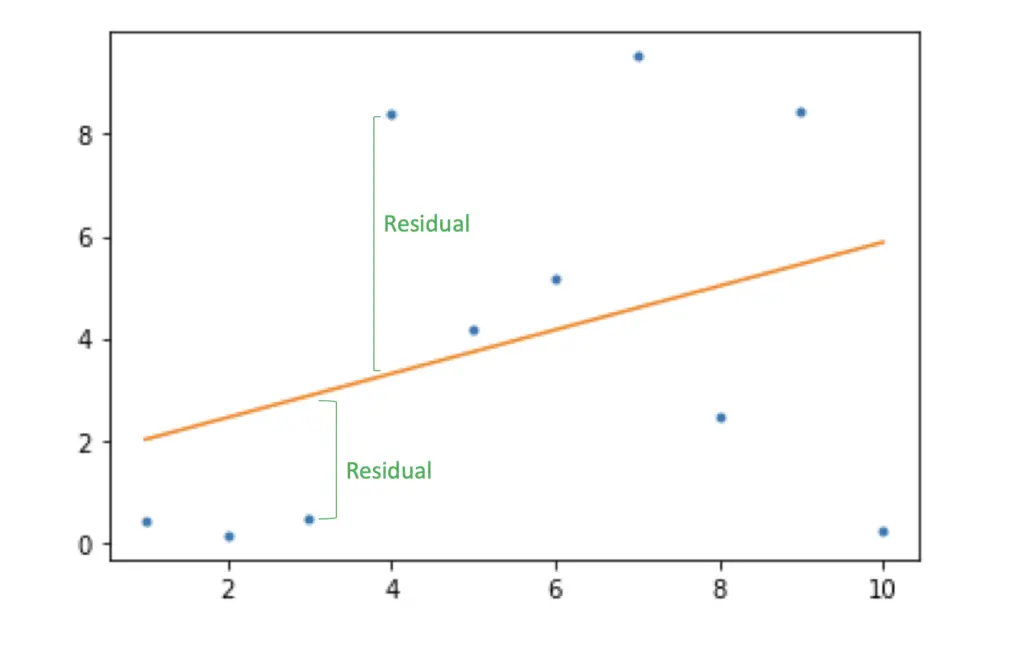
When applying the least-squares method you are minimizing the sum S of squared residuals r.
S = \sum_{i=1}^n r^2_iSquaring ensures that the distances are positive and because it penalizes the model disproportionately more for outliers that are very far from the line. The practice of fitting a line using the ordinary least squares method is also called regression.
How to find the Linear Regression Equation?
To find the least-squares regression line, we first need to find the linear regression equation.
From high school, you probably remember the formula for fitting a line
y = kx + d
where k is the linear regression slope and d is the intercept. This is the expression we would like to find for the regression line. Since x describes our data points, we need to find k, and d. In a regression scenario, you calculate them as follows.
d = \frac{\sum y \sum x^2 - \sum x \sum xy}{n \sum x^2 - (\sum x)^2 }k = \frac{n \sum xy - \sum x \sum y}{n \sum x^2 - (\sum x)^2 }Linear Regression Example: Calculating the Least Squares Regression Line
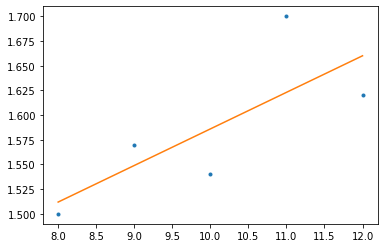
Let’s use some example data to fit the line. We want to build a simple linear regression model to predict the height of children by their age with the following data. The last bold line containers the sums of the preceding ones
| x (Age) | y (Height) | xy | x^2 | y^2 |
| 8 | 1.5 | 12 | 64 | 2.25 |
| 9 | 1.57 | 14.13 | 81 | 2.47 |
| 10 | 1.54 | 15.4 | 100 | 2.37 |
| 11 | 1.7 | 18.7 | 121 | 2.89 |
| 12 | 1.62 | 19.44 | 144 | 2.62 |
| 50 | 7.93 | 79.67 | 510 | 12.6 |
Now, let’s plug all of these values into our characteristic equation.
k = \frac{5 \times 79,67 - 50 \times 7.93}{5 \times 510 - 2500 } = 0.037d = \frac{7.93 \times 510 - 50 \times 79.67 }{5 \times 510 - 2500 } = 1.216We’ve got our characteristic linear regression equation.
y = 0.037x + 1.216
and the least squares linear regression line.
Summary
We’ve introduced residuals and the ordinary least-squares method and we’ve learned how to calculate the least-squares regression line by hand. In the next posts, we will formally introduce linear regression and learn how to calculate the least-squares regression line using Python.

{kind=link}