Machine Learning Foundations Archive

Regularization in Machine Learning
On July 31, 2021 In Machine Learning, Machine Learning Foundations
In this post, we introduce the concept of regularization in machine learning. We start with developing a basic understanding of regularization. Next, we look at specific techniques such as parameter norm penalties, including L1 regularization and L2 regularization, followed by a discussion of other approaches to regularization. What is Regularization? In machine learning, regularization
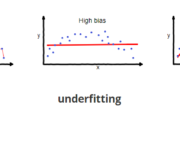
Introduction to the Hypothesis Space and the Bias-Variance Tradeoff in Machine Learning
On July 28, 2021 In Machine Learning, Machine Learning Foundations
In this post, we introduce the hypothesis space and discuss how machine learning models function as hypotheses. Furthermore, we discuss the challenges encountered when choosing an appropriate machine learning hypothesis and building a model, such as overfitting, underfitting, and the bias-variance tradeoff. The hypothesis space in machine learning is a set of all possible
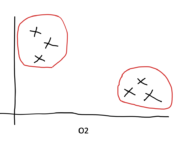
Types of Machine Learning: A High-Level Introduction
On July 21, 2021 In Machine Learning, Machine Learning Foundations
In machine learning, we distinguish between several types and subtypes of learning and several learning techniques. Broadly speaking, machine learning comprises supervised learning, unsupervised learning, and reinforcement learning. Problems that do not fall neatly into one of these categories can often be classified as semi-supervised learning, self-supervised learning, or multi-instance learning. In supervised learning,