Hashing in Java

In this post, we will discuss hashing in Java and introduce a few data structures such as hashtables and hashmaps that rely on hashing.
What is Hashing?
Hashing is a technique that allows a program to store and subsequently find an object in a large collection of items without going through every item. A hash value is like a key whereas the object is the value the key maps to. The hash value also encapsulates information about the location of the item in the collection.
Many contemporary applications rely on highly sophisticated hashing algorithms to calculate hash values. These algorithms also handle encryption which makes hashing a powerful feature in blockchain applications.
For example, you could use the length of a string as a hash value to find the string in a collection of other strings.
Handling Collisions
When using the length of the string as a hash value, you will quickly run into problems as soon as you have multiple strings of the same length. This is known as a collision. A common method to handle this problem is a process known as separate chaining. Instead of indexing one item for every hash value, you use a data structure that can hold multiple values. A linked list is a good choice here because it allows dynamic allocation (you do not have to specify the size of the linked list when you create it).
Let’s say you want to create hash values of a collection of weekdays. Some of the weekdays, such as Monday and Friday, have the same string length. The values that have the same string length are appended to the linked list with the hash value 6.
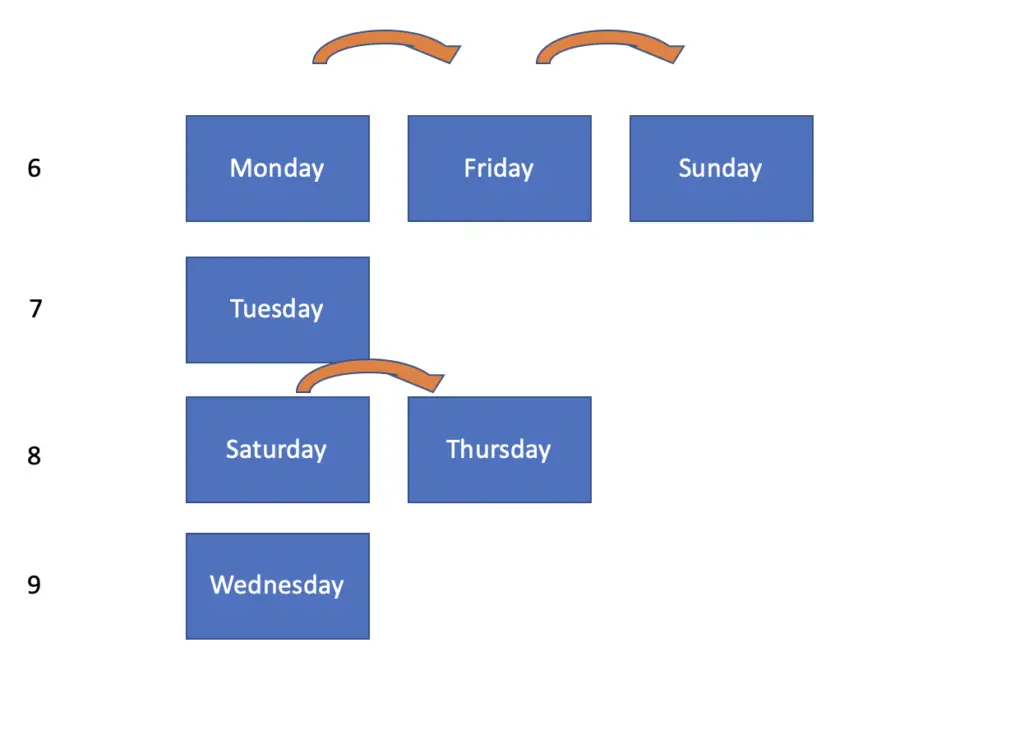
When looking up values, you check the length of your weekday, go to the linked list indexed by the corresponding hash value, and finally iterate through the linked list. That works great if your space of potential hash values is limited and you don’t have a lot of words of the same length. Weekdays only have lengths between 6 and 9 characters. Otherwise, your linked list may grow extremely large which defeats the efficiency gains of hashing.
Each location that is indexed by a hash is known as a bucket. If you are using a linked list to handle collisions, a linked list corresponds to one bucket.
To address these problems there are other techniques such as double hashing and open addressing which we won’t discuss in more detail. The general principle is that a hash value should be derived entirely from the value it is hashing, and it should be useful for location-based indexing of the item. A hash that says nothing about the location of an item in a data structure is useless.
Hashtable in Java
The hashtable is a data structure in Java that on the surface functions as a lookup table using key-value pairs. But under the hood, it is more efficient than a lookup table because keys are hashed and can be found more quickly on the basis of the hash value.
Since it functions as a lookup table, the hashtable extends the abstract Java dictionary class in addition to implementing the Serializable, Clonable, and Map interfaces.
A hashtable in Java is synchronized. If you are in a multithreaded environment, synchronized operations help prevent memory consistency errors and thread interferences by preventing concurrent access by multiple threads.
Creating a Hashtable in Java
A hashtable in Java can be created as follows.
Hashtable<Integer, String> hashTable = new Hashtable<>();
In this case, we are using an integer as a key, and a String as a value. But you are free to use pretty much any other object. Next, we can start adding objects to the hashtable.
public static void main(String args[]) {
Hashtable<Integer, String> hashTable = new Hashtable<>();
for(int i = 0; i < 2000; i++) {
String s = String.valueOf(i);
hashTable.put(i, s);
String sRetrieved = hashTable.get(i);
System.out.println(sRetrieved);
}
}
Here we are loading the table with 2000 values. As you can see, items are added using the put method and retrieved using the get method.
//add item tho hashtable hashTable.put(0, "hello"); // retrieve item from hashtable String sRetrieved = hashTable.get(0);
Hashtable Methods in Java
In addition, you have several more methods that you can look up in the Java documentation. The most important is probably the ability to get the size of the hashmap, checking whether the hashmap already contains a value, and deleting items.
//checking the size of the hashtable System.out.println(hashTable.size()); //checking whether the hashtable contains 0 System.out.println(hashTable.contains(0)); //remove an item from the hashtable hashTable.remove(0);
Hashtable with Initial Capacity and Loading Factor
In the previous example, we created the hashtable without any additional arguments. The hashtable doubles its capacity of buckets as soon as a certain threshold known as the loading factor is exceeded.
You can help Java execute the code more efficiently by specifying the initial capacity as well as the loading factor. Otherwise, Java doesn’t know how big we intend the table to be, so it has to resize dynamically. Under the hood, Java performs a resize by doubling the capacity. This involves rehashing and rebuilding the data structures to make space for new hash locations. As you can imagine, this is a time-consuming operation.
If you know the approximate number of buckets that your hashtable will contain, you can tell Java the initial capacity and beyond which threshold it should double the capacity.
int initialCapacity = 10; Float loadFactor = 0.5f; Hashtable<Integer, String> hashTable = new Hashtable<Integer, String>(10, loadFactor);
Hashmap in Java
The hashmap is similar to the hashtable with a few minor differences. First of all, the hashmap is non-synchronized. This implies, that more than one thread can use the class at the same time entailing the risk of threading issues. As a consequence of being non-synchronized, the hashmap is faster. Since Java 5, there is a thread-safe ConcurrentHashMap, which is more performant and scalable than hashtable.
Next, you can use one null key and several null values in a hashmap which is not possible in a hashtable.
The ordering of items in a hashmap is not guaranteed.
As a general guideline, use a hashmap when you are in a single-threaded environment, and the ordering of items does not matter. Use a hashtable or a concurrent hashmap when multiple threads are accessing the data structure.
Creating a Hashmap in Java
The hashmap has almost the same interface and functionality as the hashtable. It is created in the same way.
HashMap<Integer, String> hashMap = new HashMap<>();
To make execution more efficient, you can also specify the initial capacity of the hashmap as well as the loading factor.
int initialCapacity = 10; Float loadFactor = 0.5f; HashMap<Integer, String> hashMap = new HashMap<>(initialCapacity, loadFactor);
Once the number indicated by the loading factor is reached, the current capacity of the hashmap doubles. For example with an initial capacity of 10, and a loading factor of 0.5, the hashmap’s size would double once the number of items reaches 5.
Adding and Retrieving Values
You can add an item using the put method, and retrieve it using the get method with the appropriate key.
HashMap<Integer, String> hashMap = new HashMap<>(initialCapacity, loadFactor); //adding an item hashMap.put(1, "hello"); //retrieving an item String item = hashMap.get(1); System.out.println(item);
HashMap Methods in Java
For a full breakdown of the method available on the hashmap, refer to the Java documentation. Here we’ll just go through some of the more important ones such as retrieving the current size, checking for keys and values, and removing items.
//checking the size of the hashmap
System.out.println(hashMap.size());
//checking whether the hashmap contains the value hello
System.out.println(hashMap.containsValue("hello"));
System.out.println(hashMap.containsKey(1));
//remove an item from the hashmap
hashMap.remove(0);
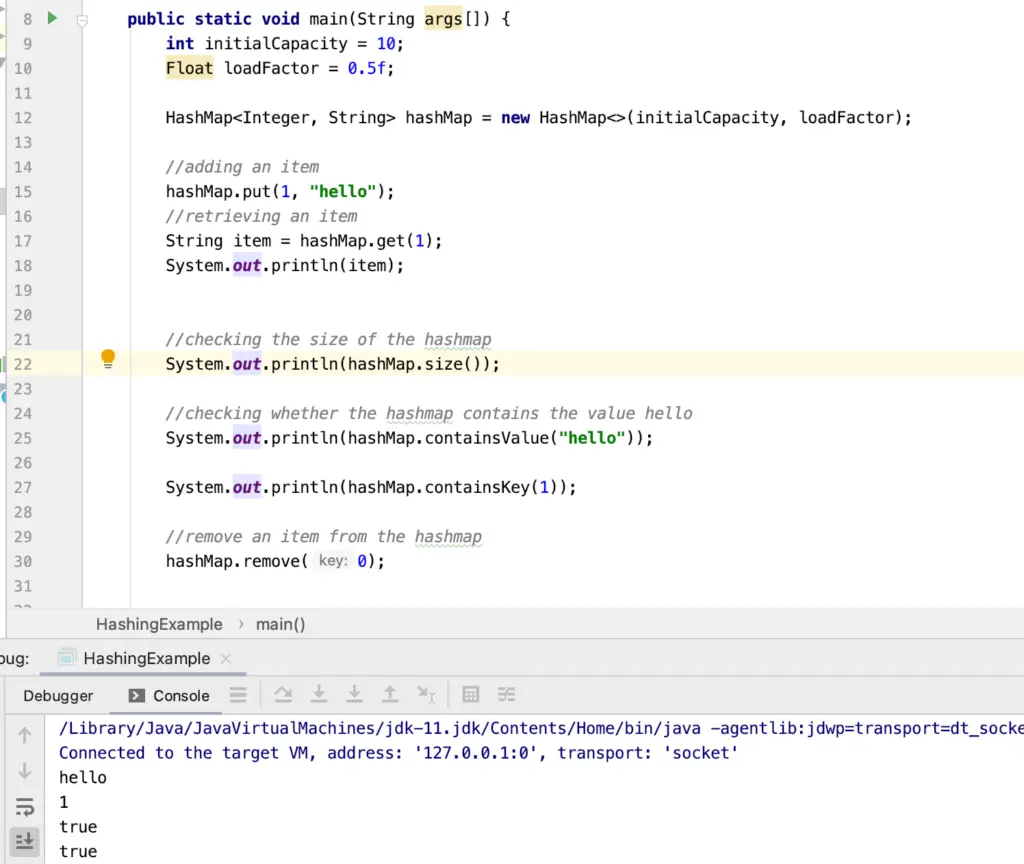
In a hashmap, there is no generic “contains” method. Rather, you check specifically for a certain key or value.

{kind=link}